Design System Given Limited Disk Interview Questions
Work through my solution to a system design interview question.
![]()
TL;DR, there are six steps to answer a system design interview question:
Step 1: clarify requirements (functional & non-functional)
Step 2: define system APIs
Step 3: sketch the high level system design
Step 4: discuss database & storage layer
Step 5: discuss core components
Step 6: add in high availability considerations and finalise the design.
This blog is a part of my "15 days cheat sheet for hacking technical interviews at big tech companies". In this blog, we focus on a step by step approach to solve a system design interview question.
The purpose of the system design interview is to assess a candidate's experience in designing large scale distributed systems. How well the candidates do in such interviews often dictates their hiring level. The performance in these interviews usually depends on 2 factors: candidates' knowledge (gained either through studying or practical experience) and the way candidates drive conversation throughout the interview.
The below are steps I usually take to solve a system design interview question to ensure my answer in a systematic way. For better demonstration, I pick up a common interview question "design a Twitter-like social networking service" and show how each step can be applied to answer this question.
General tips:
- Throughout the section, candidates are expected to take the ownership and lead the discussion. Hence, you should be active to deliver the information and clarify with the interviewer which directions they want you to go further.
- As system design interview questions are open-ended and unstructured, candidates who organise their solution with a clear plan and justify the choices have better chances of success.
Step 1: requirement clarification
As the given question is vague and it is not possible to design a system to cover all angles in 40 minutes, the very first thing you should do is to clarify the exact scope of the problem that the interviewer has in mind.
In the example of "design a Twitter-like social networking service", I will ask the interviewer following questions to clarify the requirements.
Functional requirements:
- Should users be able to register an account, delete an account and recover the password?
- Should users be able to post new tweets, delete the existing tweets and mark tweets as favorites?
- Should users be able to comment to the tweets and reply comments?
- Should tweets contain photos, videos, url links?
- Should users be able to follow their friends and celebrities?
- Should the system create and display the timeline consisting of top tweets from all the people the user follows?
- Should the system notify users for new tweets from their followees?
- Should the system suggest users who to follow?
- Should users be able to run ads to promote their tweets?
- Should the system filter violated tweets (such as pornography and spam)?
The requirements could go in different directions depending on the goals of the interviewer. For Twitter-like service, most interviewers want to see:
- Users should be able to post new tweets, follow people.
- Users should be notified for the new tweets from their followees via mobile app or via emails.
- The timeline is generated based on the followee's activities.
Non-functional requirements:
You should always assume a large scale distributed system which handles hundreds of thousands of concurrent requests, request latency is low and the system requires big storages. You don't need to make very detailed calculations, but a rough idea about the size of data, request per second (rps) plays an important role on the design decision. You can start with some assumptions such as:
- 1 billion total users with 200 million daily active users .
- 1 user posts 1 tweets and views 100 tweets per day.
- 1 tweet contains up to 140 characters. The average size is 0.3KB (two bytes per character + meta data e.g timestamp, user id..)
- 20% of tweets contain photos (average size is 200KB) and 10% of tweets contain videos (average size is 2MB).
- 1 celebrity may have 100 million followers.
- the timeline should be retrieved as fast as other requests. (latency is smaller than 200ms)
- Service has high availability.
All assumptions need to be clarified with your interviewer to make sure both of you share the same idea. After that, you need to calculate the usage based on the assumptions.
Storage Estimates:
- new tweets per day: 200M * 1 = 200M
- average size of a tweet: 0.3KB + 20%*200KB + 10%*2MB = 250KB
- storage per day: 200M * 250KB ~= 50 TB / day (5 years is about 91250 TB)
- keep 20% daily data in memory for caching: ~= 50TB * 0.2 = 10TB
Bandwidth Estimates:
- write bandwidth: 50TB per day ~= 500MB/second
- read bandwidth: ~= 100x write access ~= 50GB/second
Traffic estimates:
- write rps: 200M / per day ~= 2.3k/second
- read rps: ~= 100x read rps ~= 230k/second
Step 2: System APIs
When the requirements are clear, it is good to define the system APIs which show how clients talk to the system. You can use SOAP, REST APIs, or Graph APIs for your apis. The below are sample RESTful APIs for the Twitter-like services:
GET /api/users/<username>
GET /api/users/<username>/tweets?page=1&per_page=30
GET /api/users/<username>/followers?page=1&per_page=30
GET /api/users/<username>/followees?page=1&per_page=30
POST /api/users/<username>/tweets
POST /api/users/<username>/followers The interviewer may be interested in this part and ask you about the way to handle pagination, infinite scroll supporting. In this blog, I won't go into detail about this.
Step 3: high level system design
In this step, you sketch the main components and connections between them. At a high level, the system needs multiple application servers to serve client requests with load balancers in front of them for traffic distributions. On the backend, it requires database servers that can store data efficiently. In the case of Twitter-like service, the object file storages are also necessary to store photos and videos.
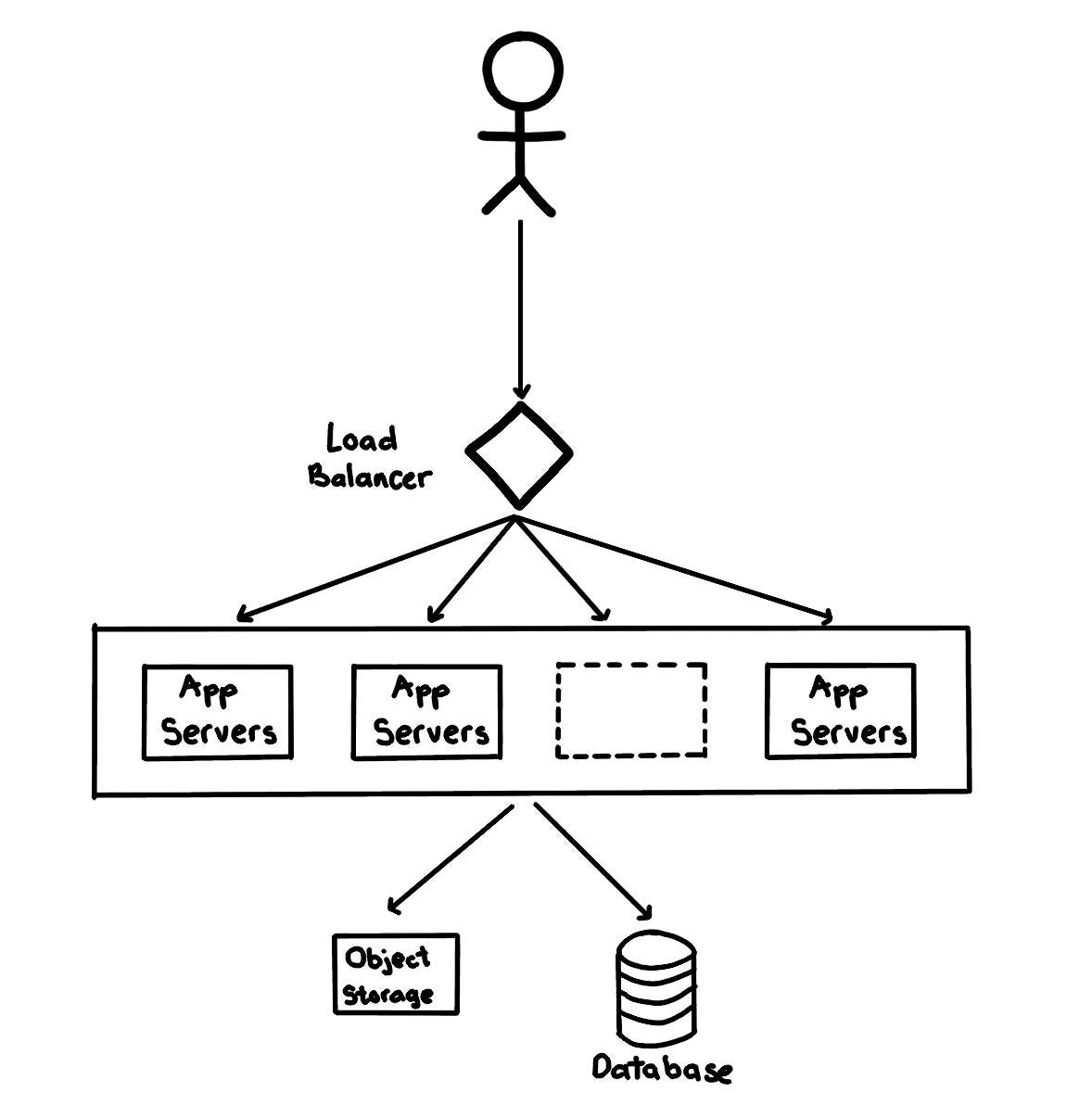
Step 4: database & storage
In this step, you go into detail about which information the system need to store and the type of database you want to choose to store different type of data.
In case of Twitter-like service, the system needs to store data about users, their tweets, their favorite tweets, and people they follow.
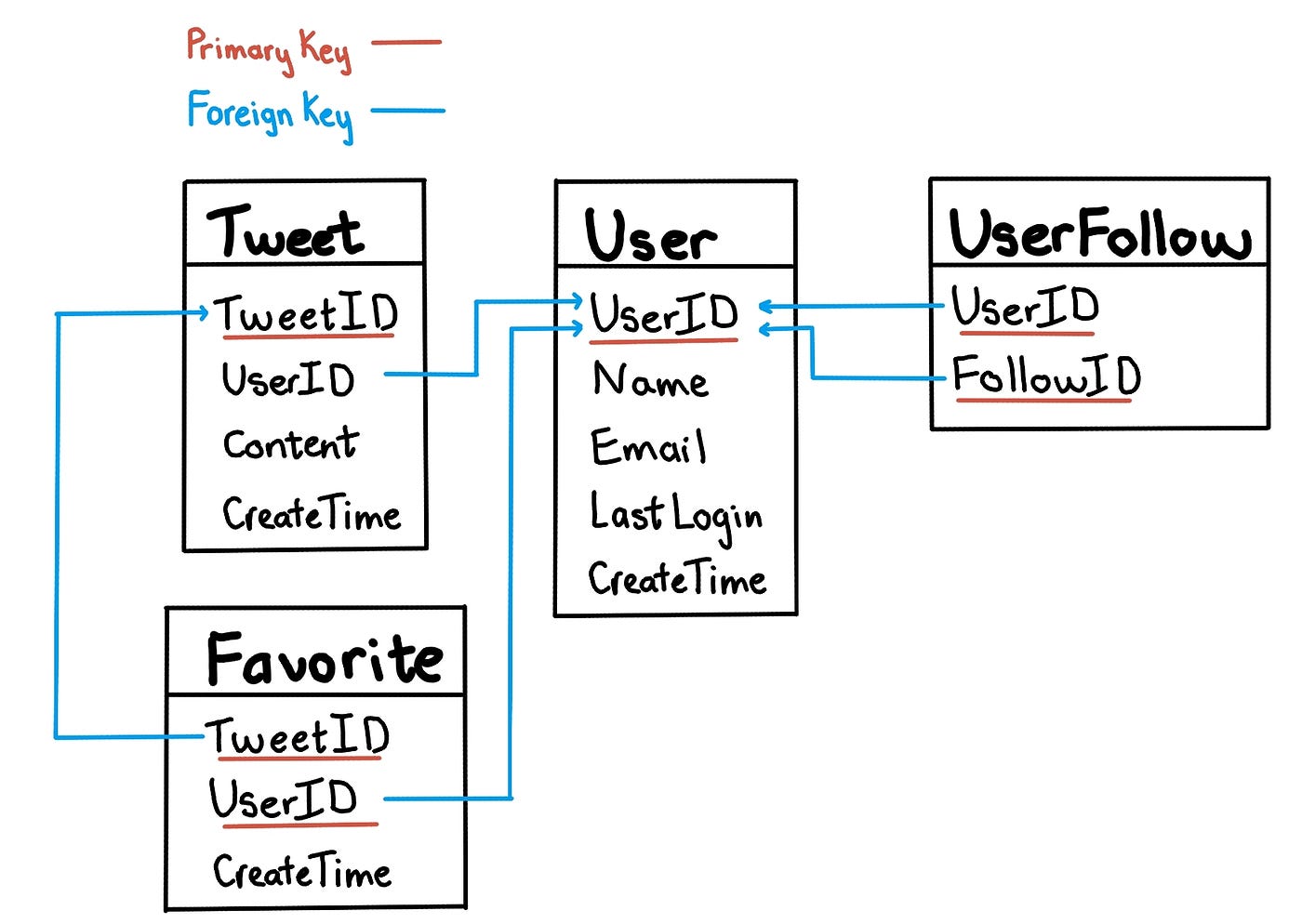
SQL vs NoSQL databases
As there are some relations between our data objects — users and tweets, the straightforward approach for storing them is to use a relational database like MySQL. However, we need to handle 2.3k rps write access and 230k read access, the performance will be an issue for SQL databases.
One option is to store the above schema in a distributed key-value store to enjoy the benefits (such as db-level sharding) offered by NoSQL. For the relationship between users & followers, we can use a wide-column datastore like Cassandra to keep the information, the 'key' would be 'UserID' and the 'value' would be the list of 'FollowID', stored in different columns. The disadvantage of this option is the difficulty in handling complex relationship queries, storing redundant data and more expensive than relational databases.
Another option is to keep using relational databases and adds data sharding logic layer as well as data cache. Some famous companies like Twitter and Facebook manage to use relational databases for handling much bigger loads than what we have in this problem.
Data sharding
Since we have a huge number of new tweets every day and our load is extremely high, one single database server can't handle them, we need to distribute our data into multiple machines in order to read/write it efficiently. There are some options to shard the data:
- Sharding based on UserID: based on hashing UserID, we map each user to a server where stores all of the user's tweets, favorites, follows, etc. This approach does not work well if users (such as celebrities) are hot and we end up to have more data and access on a group of servers compared to others.
- Sharding based on TweetID: based on TweetID, we map each tweet to a server which stores the tweet information. To search for tweets, we have to query all servers, and each server will return a set of tweets. This approach solves the problem of hot users, but, increase the latency as we need to query all servers.
- Sharding based on TweetID & create time: generating TweetId based on the create time (such as, a TweetID of 64-bit unsigned integer which has two parts, the first 32 bits is unix timestamp, the last 32 bits is an auto-incrementing sequence). We then shard the database based on TweetId. This approach is similar to the second approach and we still need to query all servers to search for tweets. However, the latency is improved as we don't need a separated index for timestamp (we can just base on the primary key TweetId) when sorting tweets by create time.
Database replication
As Twitter-like service is a read heavy system, we should have multiple secondary database servers (slaves) for each DB shard. The secondary servers are used for read traffic only. All write traffic go to the primary server and then will be replicated to secondary servers.
Data Cache
230k rps of read access is a very large scale, besides replication, we should reduce the latency further by introducing a data proxy in front of database servers to cache hot tweets and users. Application servers query data from a data proxy which quickly check if the cache has desired tweets before hitting the database.
- cache size: 20% of daily data (10TB) is a good starting point. When the cache is full and we want to replace a tweet with a newer/hotter tweet, so Least Recently Used (LRU) is a reasonable policy for this system.
- cache invalidation: we can monitor the changes in database (such as read the mysql bin logs), put the changes in a message queue, and design a service to pick up the queue message and clear the related data cache. For example, clear all cache with the prefix uid_1234_* when the user of UserId 1234 changes his nickname. There may be a short delay in the update, but it will be fine in most cases.

Object data
Tweets may contain media (photos and videos). While the metadata can be saved in the database, distributed object storages (such as HDFS or S3) should be used to store photo and video contents.
Step 5: Core components discussion
In this step, you should pick up one or two key components to discuss the design in details. For Twitter-like services, there are tweet management services, timeline services, notification services … You should discuss with the interviewer what components they care about and what they don't. I pick up timeline services for the demonstration purposes.
Timeline Generation:
In a simple case, the timeline should contain most recent posts from all the followees. It will be super slow to generate the timeline for users with a lot of follows as the system have to perform querying/merging/ranking of a huge number of tweets. Hence, the system should pre-generate the timeline instead of generating when user loads the page.
There should be dedicated servers that are continuously generating users' timeline and storing them in memory. Whenever users load the app, the system can simply serve the pre-generated timeline from cache. Using this scheme, user's timeline is not compiled on load, but rather on a regular basis and returned to users whenever they request for it.
With 1 billion users, if we pre-generate the timeline for all of them, the system needs a huge memory. Moreover, there are usually a lot of users that don't login frequently, it is a waste to pre-generate timelines for them. One way to improve it is to pre-generate the timeline based on users' action and history logs. We can build a simple machine learning model to figure out the login pattern of users and pre-generate their timelines.
Timeline Updates:
If the system treats all users the same, the interval of timeline generation for a user will be long and there will be a huge delay in his timeline for new posts. One way to improve that is to prioritise the users who have new updates. The new tweets are added in the message queue, timeline generators services pick up the message from the queue and re-generate the timeline for all followers.

New posts notification: There are different options for publishing new posts to users.
- Pull model: clients can pull the data on a regular basis or manually whenever they need it. The problem of this approach is the delay in updates as new information is not shown until the client issues a pull request. Moreover, most of the time pull requests will result in an empty response as there is no new data, and it causes waste of resources.
- Push model: once a user has published a tweet, the system can immediately push a notification to all the followers. A possible problem with this approach is that when a user has millions of followers, the server has to push updates to a lot of people at the same time.
- Hybrid: we can combine both pull and push model. The system only pushes data for those who have a few hundred (or thousand) followers. For celebrities, we can let the followers pull the updates.
Step 6: Additional Considerations
In this step, you should review the whole design and discuss some potential improvements.
DNS: Instances of the app server might be located in different data centers at different physical locations. We can add geolocation-based policy DNS to provide the client with a server IP address that is physically located closer to the client.
CDN: A content delivery network (CDN) is a globally distributed network of proxy servers, serving content from locations closer to the user. We can serve tweet media contents via CDN to improve user experiences.
Reliability and Redundancy:
We need to ensure no data loss in the service. Hence, we need to store multiple copies of each file so that if one storage server dies we can retrieve it from the other copy present on a different storage server. The same principle can be applied to other parts. We can have multiple replicas of services running in the system, so if a few services die down, the system still remains available and running. If only one instance of a service is required to run at any point, we can run a redundant secondary copy of the service that is not serving any traffic, but it can take control after the failover when primary has a problem.
Final design
Design System Given Limited Disk Interview Questions
Source: https://levelup.gitconnected.com/work-through-my-solution-to-a-system-design-interview-question-a8ea4b60513b
0 Response to "Design System Given Limited Disk Interview Questions"
Post a Comment